Runpod에서 ComfyUI 사용하기

런팟을 이용하면 생각보다 저렴한 가격에 고급 하드웨어를 대여해서 사용할 수 있다.

RTX5090, 46gb RAM의 기기를 대여하는데 시간당 0.53달러
시간당 800원 수준인데, PC방 이용료보다 저렴한 수준이다. 종량제라서 일단 10달러만 충전해서 찍먹을 해보기로 했다. 10달러를 충전하니, 이벤트로 5달러를 추가로 더 줘서 총 15달러가 충전되었고 5090 Spot기준으로 대략 25시간 정도 사용할 수 있다.
시작하기
사용하는 부분은 굉장히 간단하다. 우선 회원 가입을 하고 크레딧을 충전한 다음 Pods에서 GPU를 선택한다.
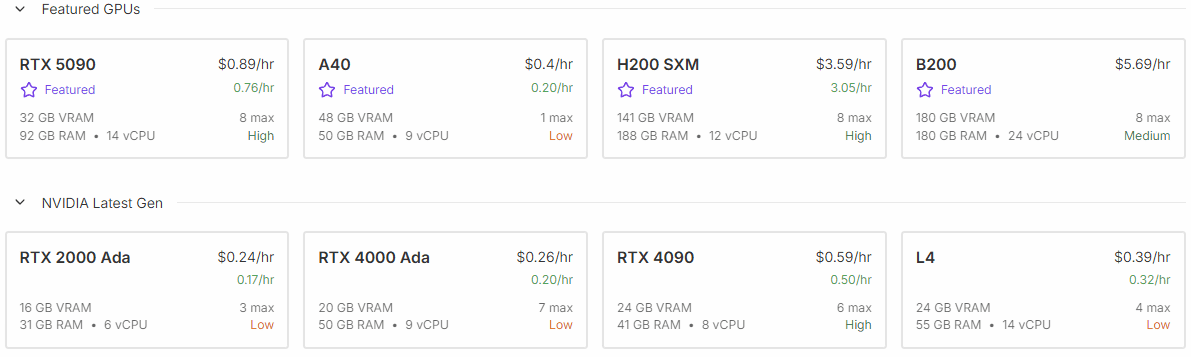
목적에 따라서 GPU를 선택하면 되는데 wan2.2을 이용한 영상 제작에는 5090을 선택하는게 좋다. 내 데스크탑이 4080인데 로컬 생성과 비교하면 5090이 2배 빠르다. 실제 CUDA 코어 갯수가 5090이 2배쯤 많은데 참 정직한 성능차이이다. 4090은 시간당 비용이 0.29달러이다. 시간당 500원 수준이다. 하지만 다음에 설명할 템플릿을 이용해 영상을 제작할 때 이슈가 좀 있다. 모델이나 해상도를 조절하는 식의 좀 더 숙달된 셋팅을 할 수 있으면 4090을 선택해도 무방하다.
템플릿 선택하기
런팟에서는 하드웨어만 대여하기 때문에 이 대여한 하드웨어에 ComfyUI를 셋팅해야 한다. 주로 파이썬을 이용해서 ComfyUI와 필요한 모델등을 설치하는 방식이다. 이 셋팅을 내가 직접 하려면 많은 시간이 소모된다. 그걸 미리 해준 다른 사람들의 셋팅을 이용할 수 있는데 그것이 바로 템플릿이다.
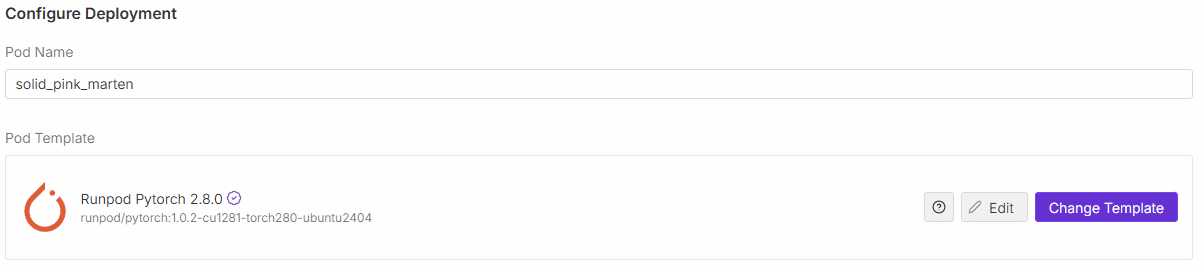
위와 같이 Pod Template 부분에서 Change Template을 선택한다.
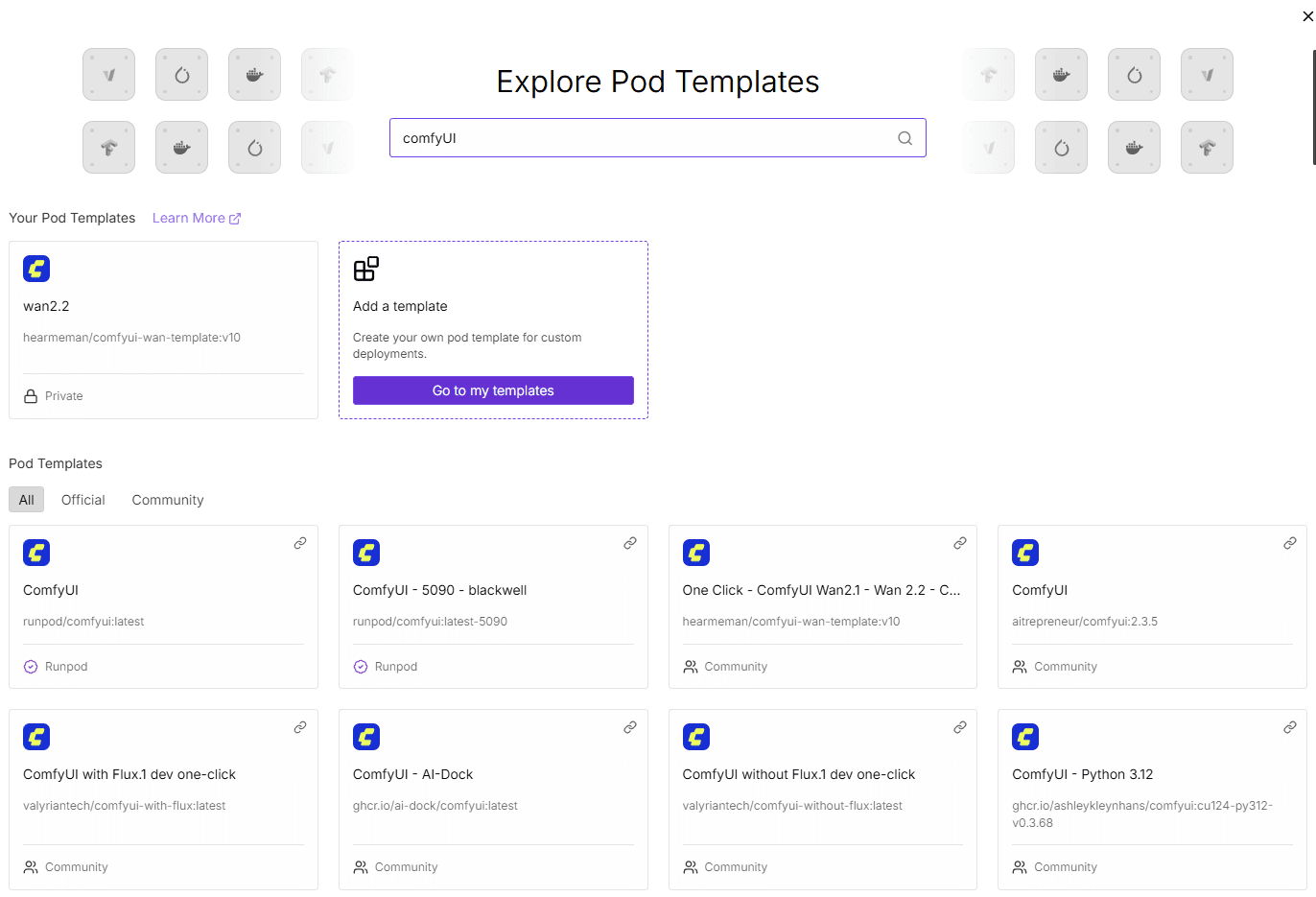
이렇게 수많은 템플릿이 존재한다.
나는 영상을 제작해보기 위해 One Click – ComfyUI Wan2.1 – Wan 2.2 – CUDA 12.8을 선택하였다.
My Template으로 만들어 놓기
템플릿을 선택하더라도 추가로 설정을 해야 하는 것들이 좀 있다. 컨테이너 디스크 용량이나 환경변수 같은 것들이다. 템플릿 그대로 쓰거나 껏다 켰다를 자주 안하면 굳이 상관 없지만 그게 아니라면 매번 입력하는것도 좀 귀찮다.
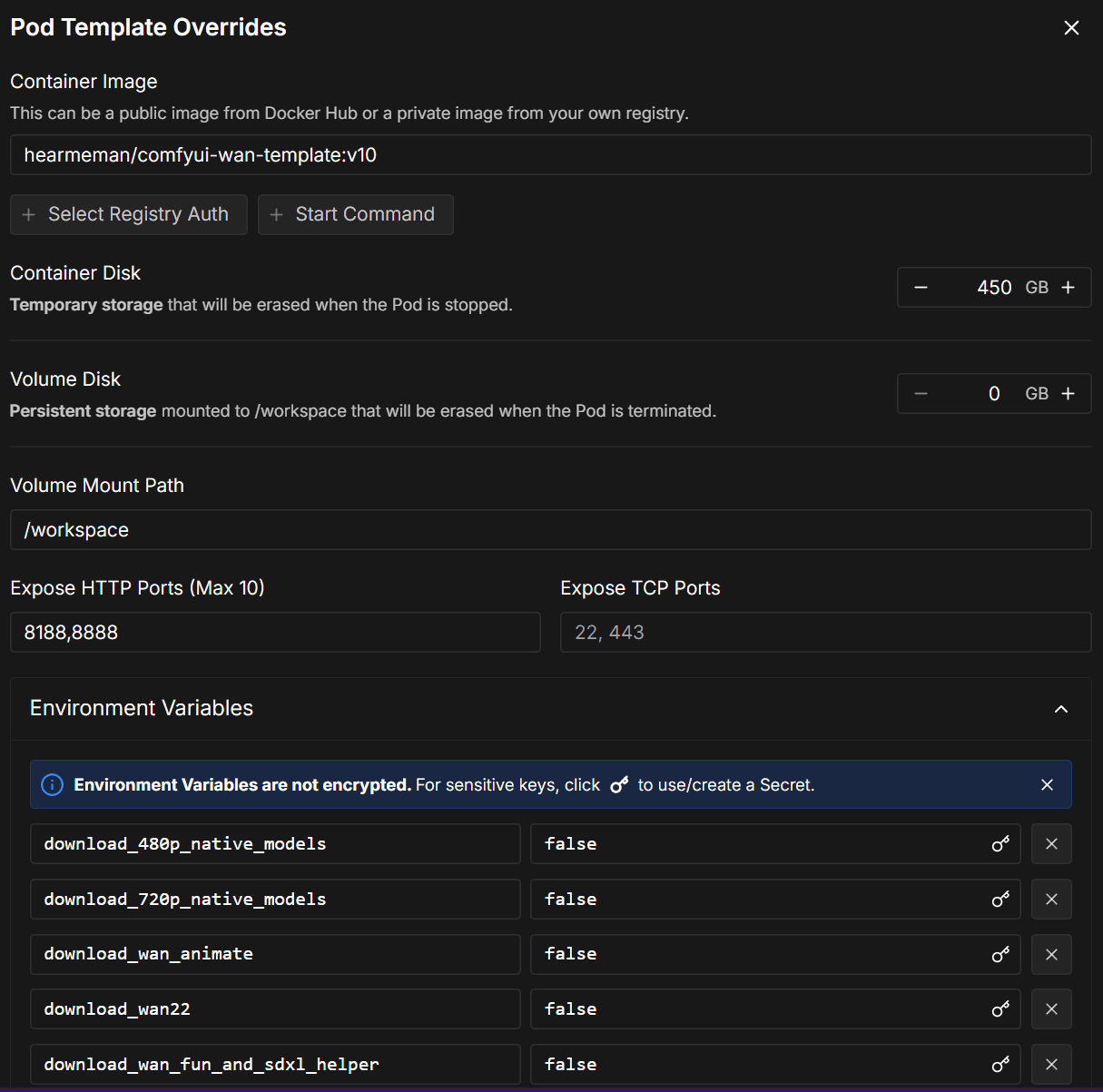
많거나 오래 걸리진 않아도 은근히 귀찬음
특히 테스트 때문에 여러번 수정하다보면 더 많이 귀찮아진다. 이럴땐 그냥 내 템플릿으로 하나 추가해서 저장해놓고 사용하는 것이 더 낫다.
내 템플릿 메뉴 가기
새로운 템플릿 추가

항목들 채워넣기
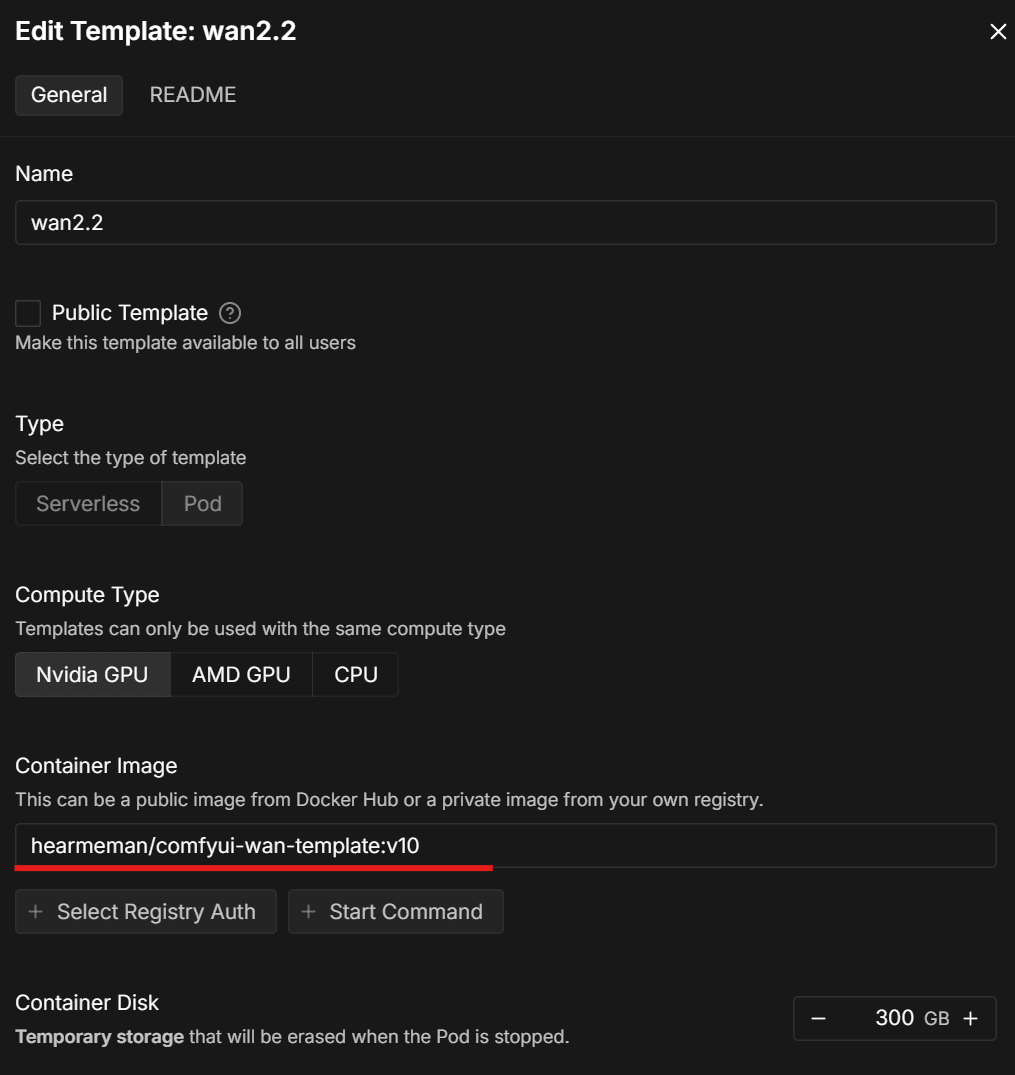
기존 템플릿의 내용을 참고해서 내용들을 채우면 된다. 가장 중요한건 Container Image이다. 도커 허브에 올라간 이미지를 선택하는 것이다. 이 이미지만 잘 셋팅되면 환경변수 부분은 자동 완성 기능으로 쉽게 채울 수 있다. 기존 템플릿에서 복사해서 새로 만들 수 있는 기능이 있으면 참 좋을것 같은데 그리고 있을것도 같은데 아쉽게도 찾을 수 없었다.
이렇게 만든 내 템플릿에 미리 나한테 맞는 값들을 입력해서 저장해놓고 템플릿 선택하는 부분에서 사용하면 된다. 그냥 처음부터 템플릿을 하나 골랐다면 내 템플릿으로 만들어놓고 사용하는걸 추천한다. 딱 한 번 사용호보고 말 템플릿이 아니라면…
Deploy Spot
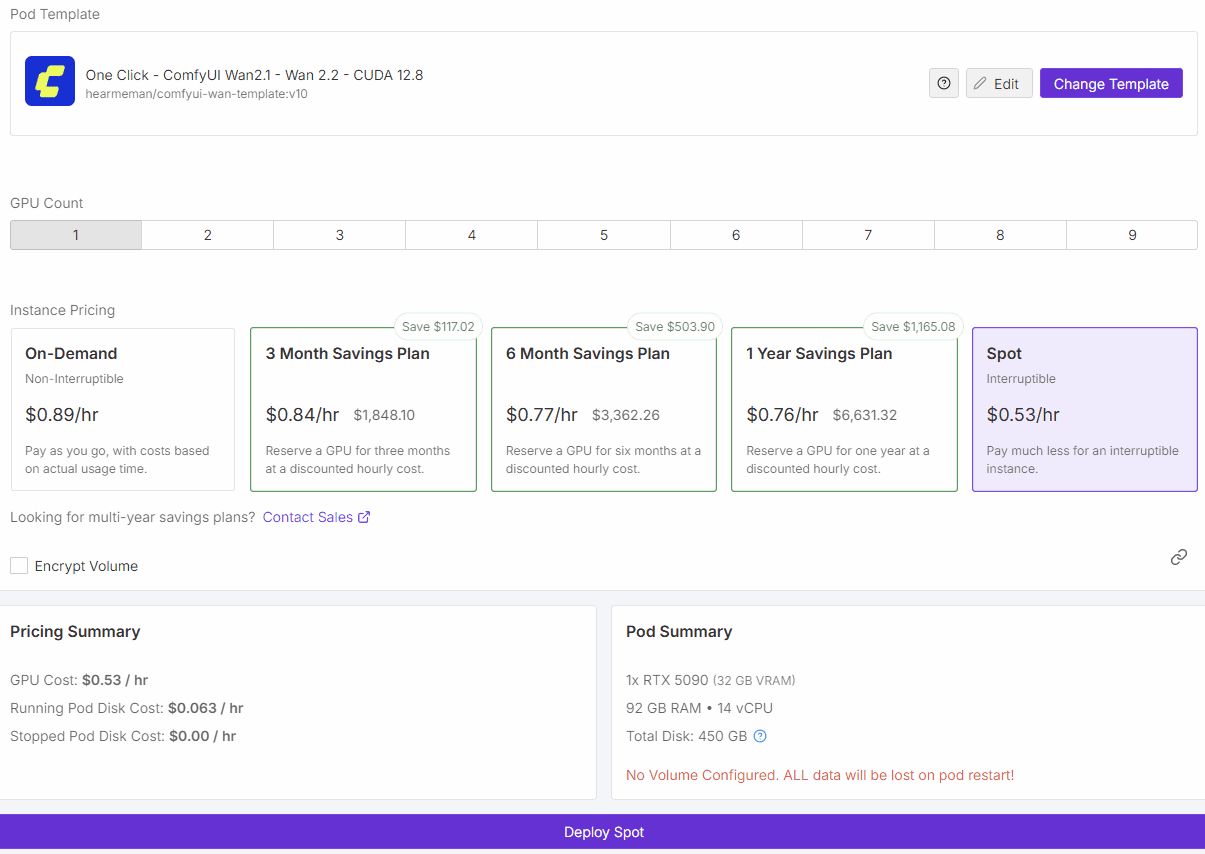
그다음엔 Deploy Spot을 선택하면 끝이다.
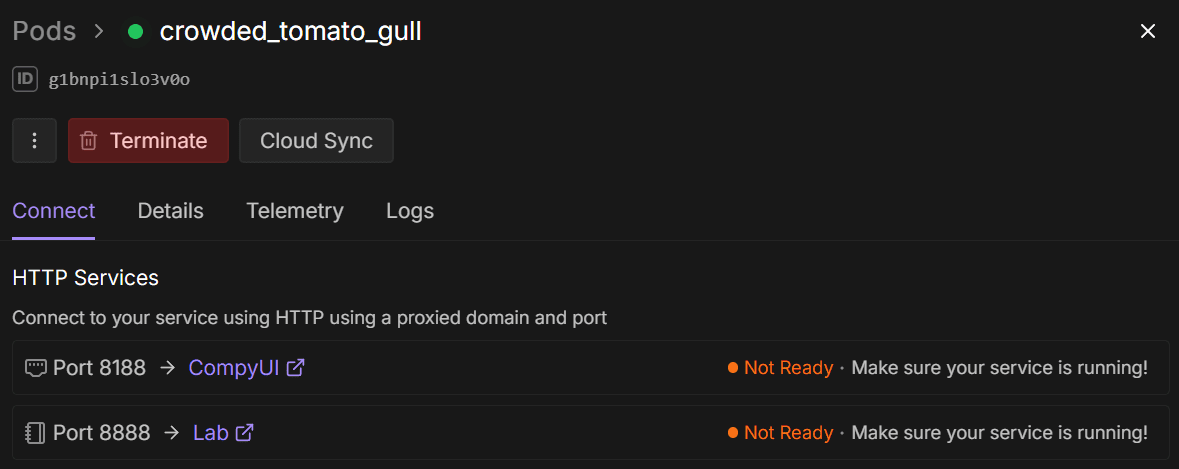
Deploy를 하면 우측에 이런 창이 뜨는데, Ready표시와 함께 초록불이 들어오면 링크를 클릭하여 ComfyUI에 접속할 수 있다. 완성된 결과물은 8888 포트 링크로 접속해서 접근 및 다운로드가 가능하다.
다운로드 속도 체크
모델이나 LoRA를 포함해서 250gb정도되는 ComfyUI를 셋팅할 때 보통 5분 내외로 셋팅이 완료된다. 이때 Log를 좀 살펴보는걸 추천한다.
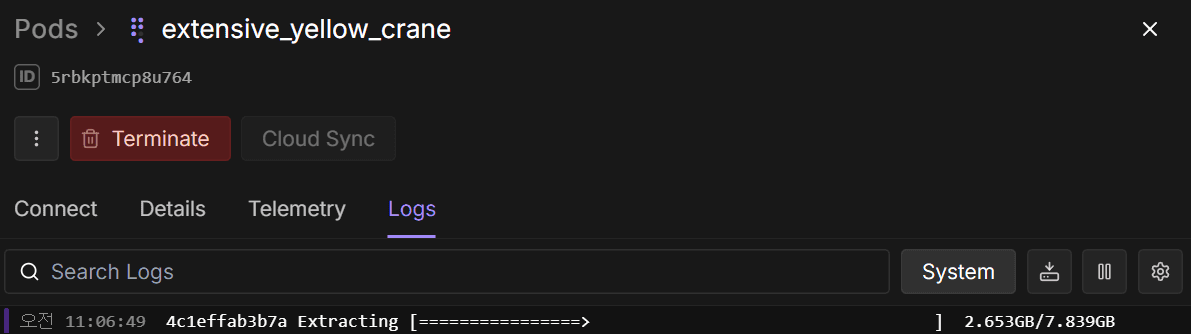
이렇게 로그를 볼 수 있는데 다음과 같이 다운로드 속도를 볼 수 있다.
[#db8bf5 1.0GiB/1.1GiB(95%) CN:16 DL:81MiB]
[#db8bf5 1.1GiB/1.1GiB(99%) CN:10 DL:81MiB]
[#db8bf5 1.1GiB/1.1GiB(99%) CN:3 DL:73MiB]특히 모델들의 용량이 매우 큰데, 이 다운로드 속도가 30MiB 이렇게 나오면 그냥 터미네이트시키고 재시도 하거나 다른 하드웨어를 선택하는게 낫다. Deploy하는 시점부터 캐쉬가 차감되는데 다운로드 속도가 저렇게 나오면 셋팅하는데 한시간 걸린다. 돈과 시간 모두 잃는 셈이다.
보통 5분 정도 걸리는 셋팅 기준으로는 다운로드 속도가 200~300MiB가 나온다. 몇번 테스트 도중 30분이 넘도록 셋팅 완료가 안되길래 로그를 보니 가끔 다운로드 속도가 굉장히 안나오는 케이스가 있었다. 30분을 기다렸더라도 추가로 30분은 더 기다려야 하는 상황이라 터미네이트 시키고 다른 하드웨어를 선택해서 5분만에 셋팅이 완료시킬 수 있었다. 이렇게 하는 것이 돈과 시간 모두 훨씬 이득이다.
에러 체크
로그를 보다보면 다음과 같은 에러를 뱉으면서 컨테이너 시작이 안되는 경우도 있다.
error starting container: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running prestart hook #0: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: requirement error: unsatisfied condition: cuda>=12.8, please update your driver to a newer version, or use an earlier cuda container: unknown문제는 따로 알림을 주지 않으므로 내가 로그를 보고 대응을 해야 한다. 위 에러의 경우는 4090을 선택해서 wan2.2 템플릿을 사용했을 때 간간히 발생하는 에러이다. 요지는 쿠다 12.8버전을 지원해야 하는 GPU가 필요한 템플릿인데 내가 선택한 GPU가 이를 지원하지 않는다는 것이다. 4090은 쿠다 12.8버전을 지원하는 GPU이다. 몇몇 머신에서 드라이버 업데이트가 안된것인가 싶기도 한데, 간간히 이런 오류가 발생한다. 이런 오류를 방치한체 멍하니 있으면 서비스는 시작되지 않은체 캐쉬만 열심히 차감되니 빨리 캐치해서 종료시켜야 한다.
워크 플로우 저장 및 로드
만들어진 템플릿을 쓰다보니 매번 워크 플로우를 수정하는 것도 일이다. 그래서 워크 플로우를 수정( 노드가 아닌 프롬프트 내용을 수정하더라도 )하면 내보내기를 통해서 json으로 저장해두고 다음에 다시 사용할때 불러와서 사용하는게 낫다.
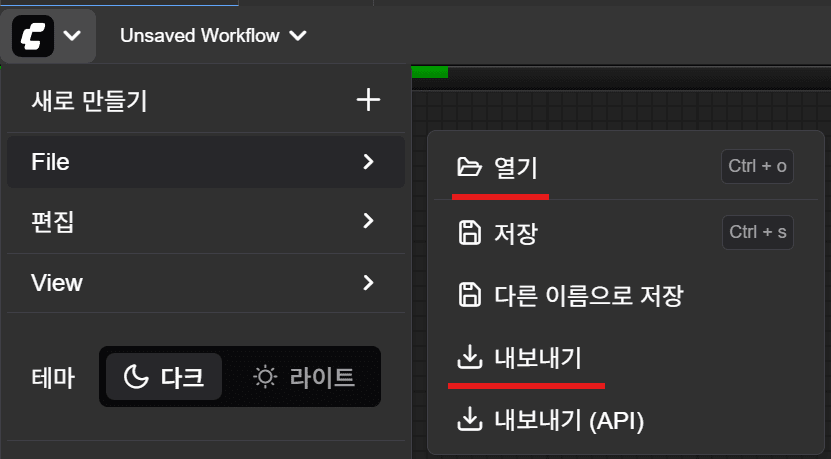
위와 같이 현재 워크 플로우를 저장하거나 로드할 수 있다.
추후 과제
템플릿에 따라 모델이나 LoRA를 미리 다운로드 받을 수 있도록 해두는 템플릿들이 있다. 그래도 여전히 내가 원하는 모델이나 LoRA, 혹은 커스텀 Node등을 미리 셋팅하는게 100% 내 마음대로 하기가 어렵다.
이 부분은 내가 템플릿 이미지를 만들어야 해소될 것으로 보인다. 결국은 파이썬 스크립트를 통해서 미리 다운로드하고 셋팅하는 부분이라서 오픈 소스로 공개된 템플릿 내용을 분석하고 모델이나 LoRA, 커스텀 Node만 내 입맛대로 변경할 수 있도록 수정하면 좀 더 나은 환경이 될 것 같다.
이 부분은 나중에 시간이 날 때 다시 한 번 다뤄보도록 할 것이다.




댓글을 남겨주세요
Want to join the discussion?Feel free to contribute!